我們都知道,人工智慧(AI)的時代即將全面到來。
在這股浪潮中,半導體、AI 資料中心、GPU 等各種專有名詞層出不窮,讓人眼花撩亂。
為了整理這些資訊,同時也為了未來的投資布局,本文將梳理這些關鍵術語,並深入探討支撐 AI 時代的「幕後主角」們。
本文內容彙整自相關書籍、各企業官網以及學術研究機構的資料,並經過筆者自行消化理解。
希望能為各位投資人提供一張清晰的技術地圖。
目錄
術語整理與技術定位
首先,我們先來釐清幾個核心概念。了解這些詞彙的位置關係,有助於後續的分析。
| 術語 | 定義與 AI 領域的關聯 |
|---|---|
| GPU 與資料中心 (GPU & Data Center) | GPU 原本是廣泛用於圖像處理的晶片,但因擅長平行運算,現已成為 AI 學習的「心臟」。例如我們常提到的 NVIDIA H100 或 B200。而將數千個這樣的 GPU 排列運作的地方,就是 AI 專用資料中心。請想像一個像體育館一樣寬廣的建築,裡面密密麻麻排列著伺服器。 |
| 頻寬與延遲 (Bandwidth & Latency) | 這是網路話題中常出現的詞彙。頻寬是指 1 秒內能流過多少數據,可以想像成水道管的「粗細」。延遲則是數據到達所需的時間,就像轉開水龍頭到水流出來的時間差。AI 需要將大量數據在精準的時機傳送給眾多 GPU,這兩者至關重要。 |
| 銅導線 vs. 光纖 (Copper vs. Fiber) | 目前的電腦大多使用銅線連接。短距離還沒問題,但若提高速度,電力消耗和發熱就會增加,且長距離傳輸訊號會變弱。相對地,光纖是利用光的閃爍來傳送數據的纜線。它適合長距離傳輸,且透過改變顏色(波長),可以同時傳送多組訊號。 |
| 矽光子與光引擎 (Silicon Photonics & Optical Engine) | 矽光子是在矽晶片上製造「光通道」的技術。想像將電子電路和光學電路整合在同一個晶片或封裝中,這是製造端的關鍵字。 光引擎則是一組將電訊號轉為光、或將光轉回電的零件總成。簡單說,裡面包含了雷射(發光)、調變器(將電波轉為光的閃爍)、光偵測器(將光轉回電)。若以汽車比喻,就像將引擎轉速傳遞給車輪的「離合器和變速箱」。 |
| CPO (Co-Packaged Optics) | CPO 是「將光引擎直接黏在晶片旁邊」的概念。以往光的入口位於「電路板邊緣」,現在則直接拉到「晶片正前方」,大幅縮短電訊號傳輸距離。 |
| OCS (Optical Circuit Switch) | 最後一個術語。OCS 是光路交換器,可以想像成在資料中心內「用光纖直接連結 GPU 機櫃的光開關」。一般的網路交換器(乙太網交換器)需要經過 (1) 光轉電、(2) 查看封包地址、(3) 轉發 這三個步驟,中間會產生延遲和耗電。而 OCS 不看封包內容,直接利用光學元件傳遞資訊,因此延遲幾乎為零,且能大幅降低功耗。這是 Google TPU 網路等正在採用且備受矚目的技術。 |
1. 現狀與課題:資料中心的「道路」正在塞車
術語準備就緒後,我們進入技術話題。首先來看看「現在到底發生了什麼問題」。
在生成式 AI 的學習過程中,需要將巨大的模型分散到數千個 GPU 上進行學習。這不是靠一台電腦單打獨鬥,而是像一個 GPU 軍團同時進行運算。
此時,各個 GPU 不僅是在計算,還在互相交換數據。它們將自己的計算結果交給附近的 GPU,並接收對方的結果,反覆進行以更新整個 AI 模型。
這裡的重點在於「如何連接這些 GPU」。
GPU 單體的性能每一代都在飛速成長。但是,連接 GPU 的網路端卻沒那麼容易變快。
用一個常見的比喻來說:GPU 已經變成了高性能跑車,但道路卻還是單線道,導致嚴重的交通堵塞。
這背後的原因在於電氣配線(銅線)的物理極限。一旦提高速度,銅線中的訊號就會模糊,傳輸距離變短。在資料中心內,要讓訊號傳輸 10 公尺、20 公尺,中間必須經過多次稱為「Retimer(重計時器)」的裝置來重建訊號。
問題不僅是距離。試圖用銅線傳送高速電訊號,每 1 位元(bit)所需的電力就會增加。在 AI 資料中心,已經有指出「通訊」而非「運算」所消耗的電力佔據了相當大的比例。如果這個比例繼續上升,同樣的電力預算下能放置的 GPU 數量就會減少。隨之而來的是冷卻負擔增加,空調設備的投資也會膨脹。
此外,越是勉強使用銅線,配線就越複雜。機櫃背面布滿了粗重且難以處理的纜線,一旦發生故障,光是找出原因就非常困難。對於資料中心營運者來說,這種「配線地獄」在營運成本上也是一個令人頭痛的問題。
因此,在 AI 資料中心領域,大家逐漸意識到:
不僅是買了幾台 GPU,更是「如何連接」決定了性能與成本。
即使使用相同的 GPU,網路設計優良的叢集與設計不佳的叢集,在 AI 性能與效率上已經開始出現巨大的差距。
2. 用「光」重鋪道路:三個解決方案
那麼,「光」是如何解決這個瓶頸的呢?請各位試著從俯瞰資料中心的角度來閱讀。
2-1. 光收發模組:光的 LAN 線

最容易導入的解決方案,其實已經實用化了。這就是稱為「光收發器(Optical Transceiver)」或「光模組」的零件,安裝在既有的基礎設施上。
觀察伺服器或交換器的正面,會看到排列著小插槽。將一個比 USB隨身碟稍大的模組「卡嚓」一聲插進去,外側則連接細細的光纖電纜。在這個模組內部,電訊號被轉換為光,而在另一端則變回電。
這種方式的優點是,伺服器或交換器附近數公分到數十公分的距離仍使用銅線,之後的長距離則交給光纖。這樣可以避開銅線不擅長的長距離問題,同時幾乎不需要改變現有的伺服器或交換器設計。
在實際現場,400G(每秒 400 Gigabit)、800G 的光模組正在迅速成為主流,甚至 1.6T(1.6 Terabit)等級的模組也正在進行試作(簡單來說,就是「數據傳輸的速度越來越快」)。
2-2. CPO 與光 I/O:將光引擎移至晶片眼前
光模組雖然帶來了顯著改善,但「從晶片到模組」這段區間仍然是銅線。到了這個階段,設計師們開始思考:
「乾脆把光引擎直接黏在晶片旁邊不就好了嗎?」
於是 CPO(Co-Packaged Optics,共同封裝光學) 誕生了。將光引擎搭載在交換器晶片或未來的 GPU 旁邊,將晶片到光入口的距離縮短至數毫米到數公分。電訊號傳輸距離越短,損耗和電力自然就越小。
這時就會用到矽光子技術。這是將光的通道或透鏡等構造直接做在交換器晶片或封裝內,實現電子與光同居的技術。
例如,全球最大的半導體代工廠台積電(TSMC)準備了名為「COUPE」的矽光子平台,打造能將電子晶片與光子晶片一體化封裝的環境。
NVIDIA 或 Broadcom 等企業也參與其中,試作次世代的光 I/O 或 CPO 產品。
光 I/O Chiplet(小晶片)的潮流也是其延伸。在主 GPU 周圍排列幾個「光專用的小晶片」,由這些小晶片負責電與光的橋接。美國半導體新創 Ayar Labs 提出的 TeraPHY 就是將光 I/O 小晶片與外接雷射結合,直接以光進行晶片間通訊的架構。
這些動作雖然才剛從資料中心的一部分開始,但可以說已經具體描繪出「GPU 叢集的血管,將逐漸從電替換為光」的未來藍圖。
2-3. OCS:將資料中心的主幹道直接變成光
光的應用場景不僅在晶片附近或機櫃之間。縱觀資料中心整體的網路結構,還存在著「交換器之間如何連接」這個更上層的問題。
這裡登場的就是 OCS(光路交換器)。
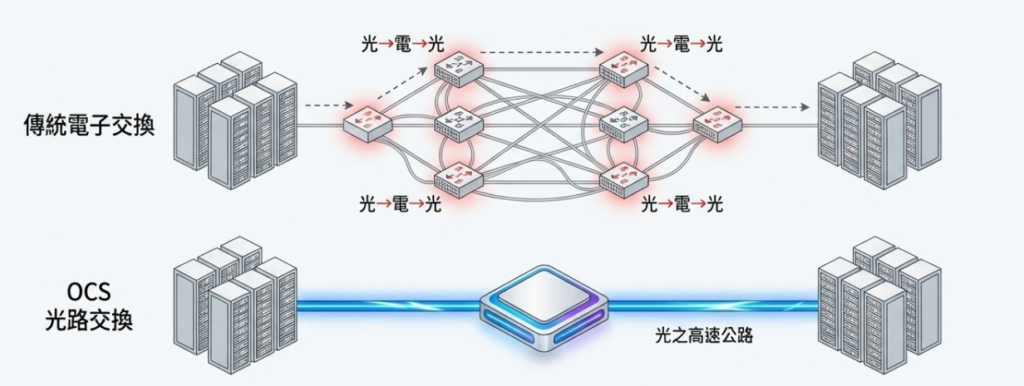
一般的交換器會暫時將光轉回電,查看封包(數據塊)的內容後再決定送往哪個埠。而 OCS 則是維持光的狀態,僅切換「從哪個埠通往哪個埠」。它就像一個巨大的光配線盤,透過改變內部的微小鏡片或元件的方向來切換光的通道。
在 AI 學習中,經常出現「在某段期間內,特定的 GPU 群組之間需要頻繁交換大量數據」的模式。這時,若用 OCS 拉一條「粗大的光水管」直通,比起堆疊多層電子交換器,能以更簡單、更低延遲且低功耗的方式組成叢集。
據報導,Google 已經在其部分資料中心運用數萬埠規模的 OCS,預測未來幾年 OCS 市場將擴大至數十億美元規模。
3. 支撐「光」的幕後的主角
了解技術故事後,接著來看看「是誰在支撐這個世界」。以下列舉的僅是代表性案例,並非個股推薦,請視為理解「有擔任這種角色的公司存在」的地圖。
3-1. Coherent 與 Lumentum:800G 模組的雙巨頭
首先是光模組領域常被提及的兩家公司:Coherent 與 Lumentum。
Coherent 是併購了光通訊元件世界級領導者 Finisar 等公司後壯大的老牌光元件廠。在資料中心領域,400G 和 800G 的光模組是其主力,調查報告顯示其在 800G 領域擁有頂級市占率。
該公司的強項在於廣泛涉獵「從雷射到模組」的所有環節。不僅是資料中心內部的短距離,連接據點與據點的長距離「同調通訊(Coherent communication)」模組也有生產,處於能同時覆蓋 AI 資料中心內部與外部的位置。
Lumentum 則是一家利用 InP(磷化銦)材料平台決勝負的公司。以能覆蓋 200G/lane 高速傳輸的元件為武器,主打製造省電的 800G 或 1.6T 模組。相較於 Coherent 業務廣泛,Lumentum 更專注於 AI 資料中心領域。作為投資標的,其波動性(Beta值)也相對較高。
這兩家公司的共通點是:「不只停留在擴充性高、靈活的(可插拔)光模組,在未來的 CPO 或 OCS 領域也擁有技術立足點」。即使 AI 資料中心的設計改變,它們也能透過改變形態持續供應光元件,建立了穩健的產品組合。說到光模組的核心,非這兩家莫屬。
3-2. 中國勢力 Innolight 與 Eoptolink:支撐 NVIDIA 的「量」
另一方面,在「量」的層面支撐近幾年 800G 模組激增的,是中國的 Innolight(中際旭創) 與 Eoptolink(新易盛通信技術)。
他們的強項在於能以合理的成本、合理的良率,大量持續生產。根據報導,NVIDIA 最新 GPU 叢集用的 800G 模組,有相當大的比例是由這兩家公司承接。
特別是 Eoptolink,積極展示對應多芯光纖(Multi-core fiber)的 800G 模組以及 1.6T 試作品等「預示下個世代」的技術,令人印象深刻。在一根光纖中放入多個核心,減少配線數量的巧思,對正與配線地獄搏鬥的資料中心營運者來說極具吸引力。
不過,中國勢力始終伴隨著美中對立與出口管制的地緣政治風險。雖然與 NVIDIA 等美系企業關係緊密,但未來管制強化會造成多大影響,始終是潛在的不安因素(Innolight 已將過半生產移至中國境外以應對風險,但若美國政府直接禁止交易則另當別論)。
3-3. 日本勢力:掌握模組與纜線的住友電工,EML 晶片高市占的三菱電機
住友電工雖以光纖和電纜聞名,但在 AI 資料中心領域的存在感也逐漸提升。該公司不僅擁有對應 800G、1.6T 的小型光收發器,還自產連接這些裝置的高密度光纜與連接器。也就是說,它能提供「不只一個模組,而是資料中心配線一整套」的提案。
此外,當 Coherent 與 Lumentum 在製造晶片或光引擎時,日本的三菱電機在該晶片(具體來說是 EML 晶片)領域擁有世界頂級的實績。雖然因業務多元容易被忽略,但在所謂的光電融合領域,三菱電機確實擁有強項。
3-4. Broadcom 與 Marvell:掌握模組內「大腦」的半導體
前面提到的企業多是處理「光本身」的公司。若再往內深入一步,光模組內部也有半導體的世界。
這裡的主角是 Broadcom(博通) 與 Marvell(邁威爾)。
800G 或 1.6T 光模組的運作,背後有負責高速訊號處理的 DSP(數位訊號處理)或 PHY 晶片(負責電訊號與數位數據轉換)支撐。這就像是負責整理訊號、修正錯誤的「幕後大腦」。
Broadcom 除了提供交換器用的客製化晶片(ASIC)以及連接電腦網路的 NIC(網路介面卡),也提供 200G/lane 等級的 PHY 和內建雷射驅動器的晶片。撇開技術細節,重點在於「從交換器到 NIC,再到模組內的訊號處理,全部都能在 Broadcom 買齊」這點,簡化了大型雲端企業的設計工作。
Marvell 則是「光模組用 PAM4 DSP」的領導者,這是一種能讓更多數據高效傳輸的技術。其推出了名為 Ara 的 3nm 世代 DSP 平台,宣佈能一氣通貫支援從 400G 到 1.6T 的需求。同時也涉足資料中心間同調通訊用的 DSP,掌握了資料中心內部與外部兩端的「訊號處理大腦」。
3-5. Amphenol:連接器產業的巨人
相對於 Coherent 或 Lumentum 位於光收發器的核心,Amphenol 則是位於光收發器前後端的高速連接器領域的巨人。
該公司雖涉足國防、量子運算等廣泛領域,但產品核心始終是「連接器」。在 AI 資料中心用的高速互連領域,已建立了支配性的地位。
3-6. 其他周邊企業
除了模組與連接器,提供測試裝置或研磨裝置的周邊企業也受到矚目。日本勢力中,測試裝置的 Santec HD、光連接器端面研磨機與檢查裝置的精工技研等均為代表。雖然「資料中心 × 光」的主角是 Lumentum 或 Coherent 這樣直接處理光的企業,但 Santec 和精工技研則位於受惠於這些需求的位置。
如何看待「資料中心 × 光」這個主題
比起 GPU 或半導體的話題,光與配線的故事或許顯得樸實無華。然而,在 AI 資料中心內部,正靜靜地發生著主角輪替。
GPU 單體的性能未來仍會持續進化。但能否發揮出那份性能,已經進入了「很大程度取決於如何連接 GPU」的時代。
透過光模組加速從銅到光的接棒;透過 CPO 或光 I/O 將光引擎拉到晶片眼前;以及透過 OCS 將資料中心的幹線道路本身換成光。
這些技術都在 AI 熱潮的背後,展開了安靜卻激烈的競爭。
作為投資人,在追蹤相關新聞或財報時,試著帶著「這家公司是做 GPU 的?還是支撐 GPU 連接的光通訊部分的?」這樣的觀點,即便同樣是 AI 這個關鍵字,你所看到的世界應該會有所不同。
NTT 是日本企業中屈指可數的大企業,也是我們熟悉的高股息股票。筆者本身也有投資 NTT,而決定投資的理由之一正是 IOWN 構想。

2025年11月28日、來自 NTT 的股息匯款通知書。
為什麼我在投資日本的高股息股票?請閱讀我的目標。


筆者觀點:這與 NTT 的 IOWN 有何不同?
IOWN 在 2024 年與台灣開通了世界首條國際間 IOWN,建立了連結日本與台灣約 3000 公里的全光網路。

這與前面提到的技術有何不同?筆者的解讀如下:
- IOWN:國家到地球規模的全光架構(All-Photonics)。
- OCS 或 CPO:支撐其中 AI 資料中心部分的「局端技術」。

首先,NTT 的 IOWN 構想是「讓全日本、全世界的通訊,盡可能從頭到尾都維持光的形式傳輸」。現有的網路被切分為家庭 LAN、基地台接取線路、連接都市的骨幹網路、資料中心間線路等多個區段。每個交界處都有路由器或交換器,將訊號轉回電再轉回光...這個反覆過程累積了延遲與電力損耗。
IOWN 的 All-Photonics Network(APN,全光網路)的想法是「既然如此,乾脆從頭到尾盡可能用一條光的道路連接吧」。從用戶端的收發器到對方的終點,在電信業者的網路中,不轉回電訊號,直接用波長的隧道貫通。目標是在 2030 年左右實現電力效率 100 倍、容量 125 倍、端對端延遲 1/200 這種極具野心的數字。
另一方面,剛才提到的 OCS(光路交換器),規模則更加「局端」。對象主要是 AI 與 HPC(高效能運算)用的巨大 GPU 叢集,主題是「單一資料中心內部,或資料中心之間如何連接」。
這裡的問題是機櫃與機櫃之間往返流量的壅塞。以往是透過多層電子交換器處理,現在則是利用 OCS 這種光配線盤,將需要的機櫃用光纖直連,以避開壅塞。
因此,兩者的共通點都是「維持光的狀態連接,減少轉回電的次數」。IOWN 也說明要重新檢視現有路徑,盡可能打造光直通終點的網路;OCS 內部僅用 MEMS 鏡片分配光,不解析封包,在這個意義上也是「電路交換的全光網路」。
差異在於,那條光的道路走在哪裡。
IOWN 的範圍包含東京到大阪、東京到洛杉磯這種都市、國家、資料中心間的幹線,以及 5G/6G 的前傳網路,甚至包含企業與家庭的接取線路,是「將奔馳在全日本的高速公路與幹線道路,全部重新設計為『光 Only 網路』」的規模。這是偏向電信業者與雲端業者的社會基礎設施話題,規格也是透過 IOWN Global Forum 這種國際團體來制定,包含生態系的建立。
OCS 則是更偏向企業廠區內、資料中心廠區內的話題。例如在 Google TPU 中,「今天想把這 1024 台組合成巨大叢集,所以把這些機櫃群用光直連」、「下個工作要換別的組合」這類,作為即時重組 GPU 機櫃間配線的光開關來使用。與其說是處理全國流量,不如想成是「如何更快、更省電地完成特定 AI 工作」的局端最佳化工具。
