── Haiku、Sonnet、Opus、GPT-5.5、Gemini、Qwen、DeepSeek、Grok,讓 8 個 AI 真刀真槍下判斷的紀錄
前言 ── 「所以,用 AI 到底能不能賺?」用數據回答
從第1篇建好環境、第2篇找出規則之後,我從黃金(XAUUSD)15 年的數據裡,找出了「星期四下跌,就在星期五的日內買進(賭跌深反彈)」這條規則,加上 ATR 停損後,得到一條「基準線」:勝率 59.6%/獲利因子(PF)1.50。
這條基準線的「規則」本身,是我在第2篇和 AI(=我)一起找出來的。但這個基準,個別的買賣判斷並沒有用 AI,只是機械式地執行規則而已。
於是第3篇的問題是:
🎯 在這條規則之上,加上「AI 的判斷」,能不能超越基準?
具體來說,就是把過去 386 次「星期四下跌→星期五」,一次一次交給 AI 判斷「這個星期五要做?還是略過?」,只用 AI 選中的星期五來交易,看看成績如何。如果 AI 能幫我避開那些「快崩盤的危險星期五」,理論上就能超越基準 ── 這是我的假設。
而且,這次不是只用一個 AI,而是把現在主流的 8 個 AI 全部並排,讓它們同場競技。
/
⚠️ 先聲明:本系列不是投資招攬。所有數字都是歷史回測,不代表未來。實際下單請用最小單位、自負風險,我自己也是謹慎進行。


實驗規則 ── 「公平」與「防作弊」
要讓 8 個 AI 競爭,條件不一致就沒有意義。所以全模型共用:
- 相同的提示詞/相同的輸入資料/相同的 386 次星期五/輸出的解讀方式也相同
- 只給「星期五開盤時就能知道的特徵」(星期四的漲跌、近 5 日走勢、趨勢、波動率等)
而最重要的一道工夫,是 「防作弊」。
🔒 不告訴 AI 日期,也不給絕對價格。 如果告訴它「2020 年 3 月 13 日」,AI 就會從學習到的知識裡想起「啊,那是新冠暴跌前後」而做判斷(=事後諸葛的作弊)。所以我把日期和絕對價格都藏起來,只給「盤勢的形狀」讓它判斷。
參賽的 8 個模型(2026 年 6 月時的最新等級):
| 提供商 | 模型 |
|---|---|
| Anthropic | Claude Haiku 4.5 / Sonnet 4.6 / Opus 4.8 |
| OpenAI | GPT-5.5 |
| Gemini 2.5 Pro | |
| 阿里巴巴 | Qwen3-235B |
| DeepSeek | DeepSeek V4 |
| xAI | Grok 4.3 |
💡 連線方式:Claude、GPT、Gemini 直接用各家 API,Qwen、DeepSeek、Grok 透過 OpenRouter(用一個窗口呼叫多家 AI)。當然不下單,只讓它判斷(read-only)。
🔎 關於這次實驗的前提(給認真的讀者):模型名稱以 2026 年 6 月實測當天 API/OpenRouter 顯示名稱為準,版本日後可能更新,本文結果只代表當次實驗。每個星期五只判斷一次(非多次平均),且最新的推理模型無法統一固定 temperature,因此同樣的提示詞重跑也可能略有變動。給 AI 的特徵只有「星期四漲跌、近 5 日報酬、與均線關係、波動率(ATR)、開盤跳空」等開盤前資訊;停損為 1.0×ATR、成本以來回 $0.30 估算。最後,這是樣本內(in-sample)的歷史回測比較,不是樣本外驗證。
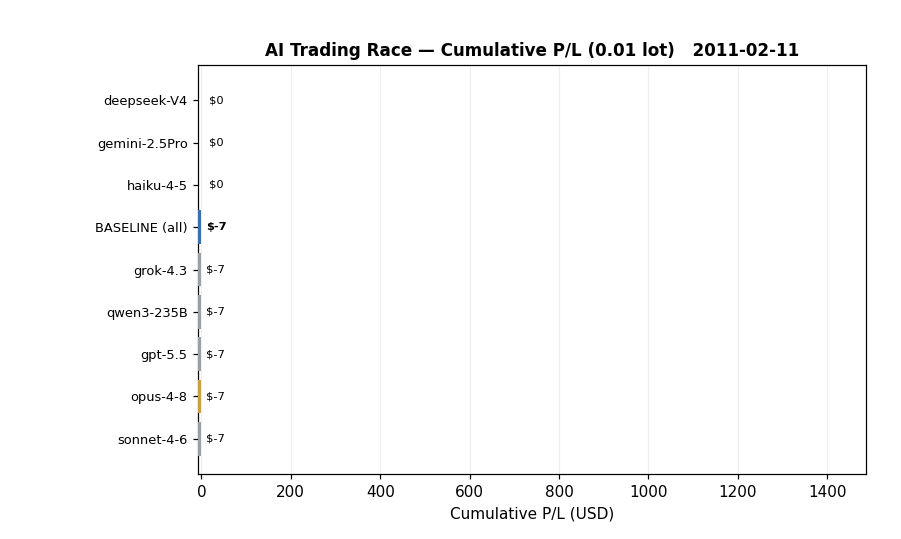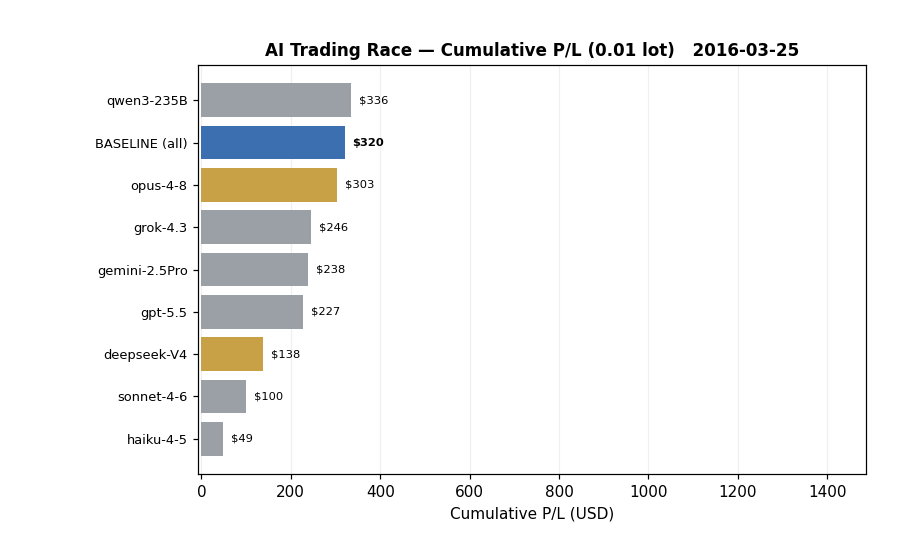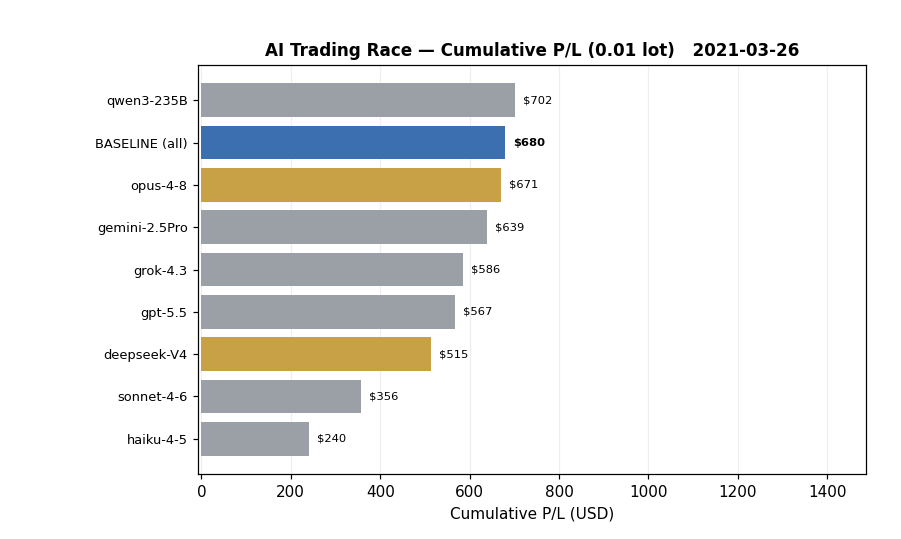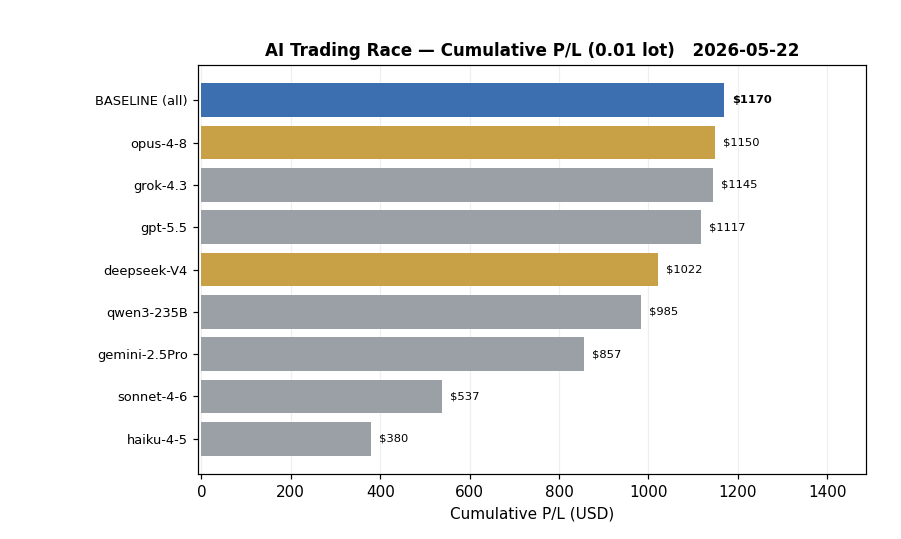
結果① 排名 ── 沒有人能「超越」基準
先看大家最想知道的「總損益(0.01 手/15 年)」排名。
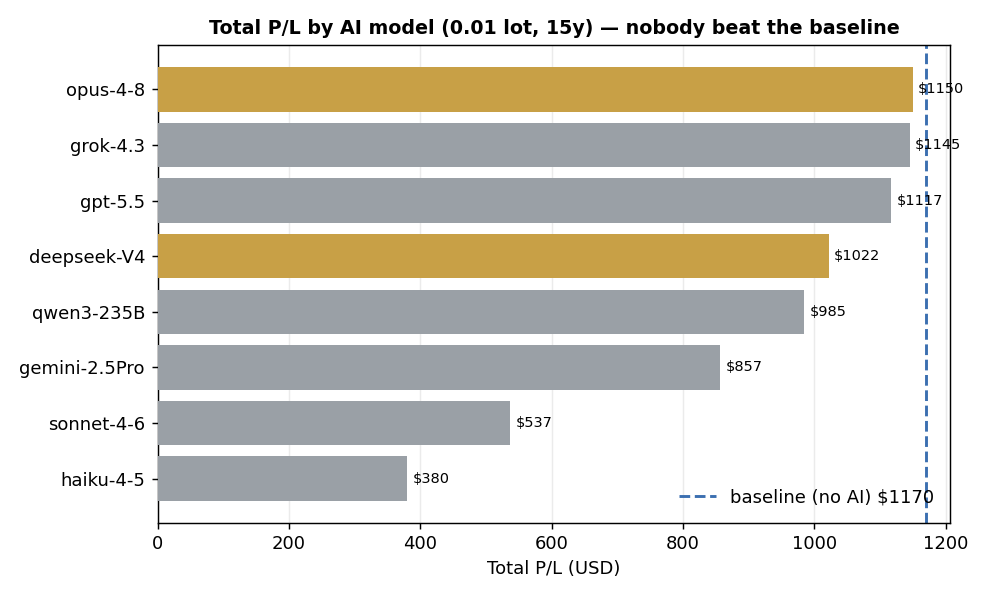
| 模型 | 取單數 | 勝率 | 總損益 | PF | 夏普 | 最大回撤 |
|---|---|---|---|---|---|---|
| 基準(無 AI/全部都做) | 386 | 59.6% | $1,170 | 1.50 | 0.83 | -$217 |
| Opus 4.8 | 380 | 59.7% | $1,150 | 1.57 | 0.86 | -$178 |
| Grok 4.3 | 372 | 59.7% | $1,145 | 1.54 | 0.82 | -$169 |
| GPT-5.5 | 377 | 59.7% | $1,117 | 1.52 | 0.80 | -$178 |
| DeepSeek V4 | 316 | 59.5% | $1,022 | 1.63 | 0.81 | -$147 |
| Qwen3-235B | 377 | 59.7% | $985 | 1.43 | 0.82 | -$217 |
| Gemini 2.5 Pro | 361 | 59.0% | $857 | 1.41 | 0.78 | -$188 |
| Sonnet 4.6 | 242 | 54.5% | $537 | 1.33 | 0.49 | -$167 |
| Haiku 4.5 | 176 | 54.0% | $380 | 1.30 | 0.40 | -$166 |
結論,某種意義上令人洩氣。
以總損益來說,超越「基準($1,170)」的 AI,一個都沒有。
原因很單純。AI 越是增加「略過」,就越會把好的星期五一起錯過,總額一定會下降。「全部認真地做」,比想像中更強。
📈 到目前為止都是「最終結果」,接下來用快轉的「賽跑」看看 這 15 年是怎麼累積起來的。藍色的「BASELINE」就是無 AI 的基準。到最後,沒有一個 AI 能超過這條藍線。
結果② ── 但在「品質與風險」上,有人超越了
不過,指標不是只有「總額」。用對風險的效率來看,故事就不一樣了。
- 🥇 DeepSeek V4:PF 1.63(全模型最高)、最大回撤 -$147(最小=最安全)。386 次裡只做 316 次,在維持勝率的同時大幅削減了風險。=「最聰明地減量」。
- 🥈 Opus 4.8:夏普值 0.86(最高)、總額也幾乎打平。平衡最佳。
也就是說,「賺更多」做不到,但「賺一樣多、卻更安全」做得到 ── 確實有(少數)這樣的 AI。
結果③ ── 越聰明越「全部都做」,越便宜越「砍過頭」
這裡很有意思。把 AI「略過了多少」和「成績」並排,出現了清楚的傾向。
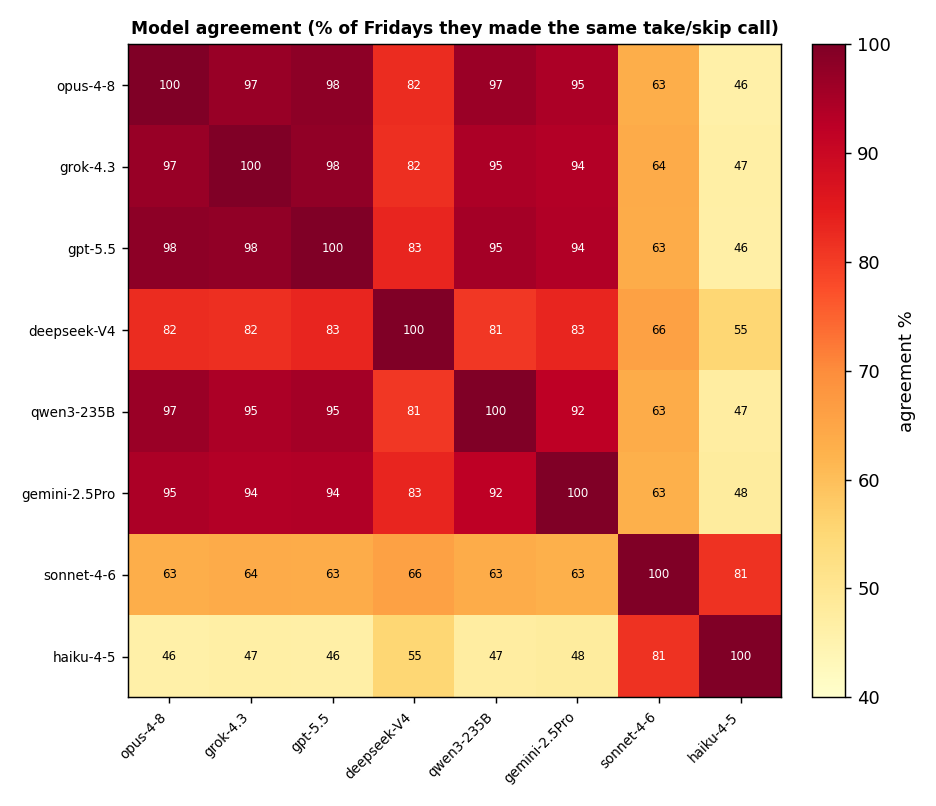
- 聰明的大型模型(Opus、GPT-5.5、Grok、Qwen)幾乎「全部都做」(386 次中做了 372–380 次)。=結果跟基準幾乎一樣。彼此的判斷也92–98% 一致。
- 便宜的小型模型(Haiku、Sonnet)砍過頭而自滅。Haiku 只做了 176 次,勝率 54%、利潤只剩基準的三分之一。
於是把「做了的星期五的平均」和「略過的星期五的平均」相比,就能一眼看出「選得好不好」(做了的比較高,就是聰明地捨棄)。
| 模型 | 略過數 | 選別分數(做−略過) | 評價 |
|---|---|---|---|
| Grok 4.3 | 14 | +1.33 | ✓聰明地捨棄 |
| DeepSeek V4 | 70 | +1.12 | ✓聰明地捨棄(量與質兼具) |
| Opus / GPT-5.5 | 6 / 9 | -0.35 / -2.91 | 幾乎全做=形同沒過濾 |
| Haiku / Sonnet | 210 / 144 | -1.60 / -2.17 | 把好的星期五捨棄而自滅 |
| Gemini / Qwen | 25 / 9 | -10 / -18 | 罕見的略過剛好砸中「最賺的星期五」 |
能做出有意義的「聰明選別」的,其實只有 DeepSeek。多數 AI 不是「全部都做(=跟基準一樣)」,就是「捨棄錯的那些」。
順帶一提,多數決(共識)也沒用。8 家裡有 5 家以上說「做」的星期五才做,成績仍低於基準;全體一致才做的話只有 149 次、$296,最差 ── 「大家都說要做的星期五」,並不是最好的星期五。
★ 最重要的發現 ── AI 無法超越的「根本原因」
最後,把所有模型「略過的星期五」一個一個對照實際結果,跑出了一個衝擊性的事實。
看看過去 15 年最慘的星期五(2026 年 3 月 20 日/-$161)──
✅ 8 家裡有 7 家,正確地略過了。 理由也很到位:「Falling knife(落下的刀):5 日內 -8.5%、在兩條均線之下、高波動」「加速的賣壓,是恐慌不是普通的回檔」等。AI 確實看穿了「暴跌」。
「喔,AI 很聰明!」對吧。但是 ──
| 星期五 | 8 家的判斷 | 實際結果 |
|---|---|---|
| 2026-03-20 | 7/8 家「落下的刀」→ 略過(只有 Qwen 進場) | -$161(略過正確 👍) |
| 2026-02-06 | 5/8 家「落下的刀」→ 略過(GPT-5.5/DeepSeek/Grok 進場) | 反彈 +$205(略過失敗 👎) |
同樣的「落下的刀」判斷,一個正確、一個大失誤。連理由的用詞,幾乎都一樣。
🔑 這就是 AI 無法超越基準的根本原因。 「崩盤(落下的刀)」和「可以買的絕佳回檔」,在星期五開盤的那一刻,是無法分辨的。兩者都長著「最近跌得很兇、很可怕」的形狀。所以人看、最新的 AI 看,都會用同樣的詞下判斷。
而諷刺的是 ── 「避開暴跌的聰明」和「敢買可怕回檔的勇氣」,是一體兩面。把前者加強,就會連後者(=這個策略的獲利來源)一起殺掉。所以 AI 才無法穩定地超越機械式的基準。
成本 與 時間 ── 「貴、慢」不等於「聰明」
也談談實務。8 模型 × 386 次=3,088 次判斷花了多少:
| AI 模型 | 使用 token | 估算成本 |
|---|---|---|
| Claude Opus 4.8 | 178k | ~$7.1 |
| Gemini 2.5 Pro | 685k | ~$5.9 |
| Grok 4.3 | 300k | ~$0.9 |
| Claude Sonnet 4.6 | 132k | ~$0.7 |
| GPT-5.5 | 155k | ~$0.6 |
| DeepSeek V4 | 359k | ~$0.4 |
| Claude Haiku 4.5 | 140k | ~$0.3 |
| Qwen3-235B | 118k | ~$0.02 |
| 合計 | 207 萬 | 約 $16 |
成本為估算(Qwen/DeepSeek/Grok 三家由 OpenRouter 實測合計 $1.36)。光是 Opus 和 Gemini Pro 就占了約 8 成。Qwen 更是驚人的 $0.02。
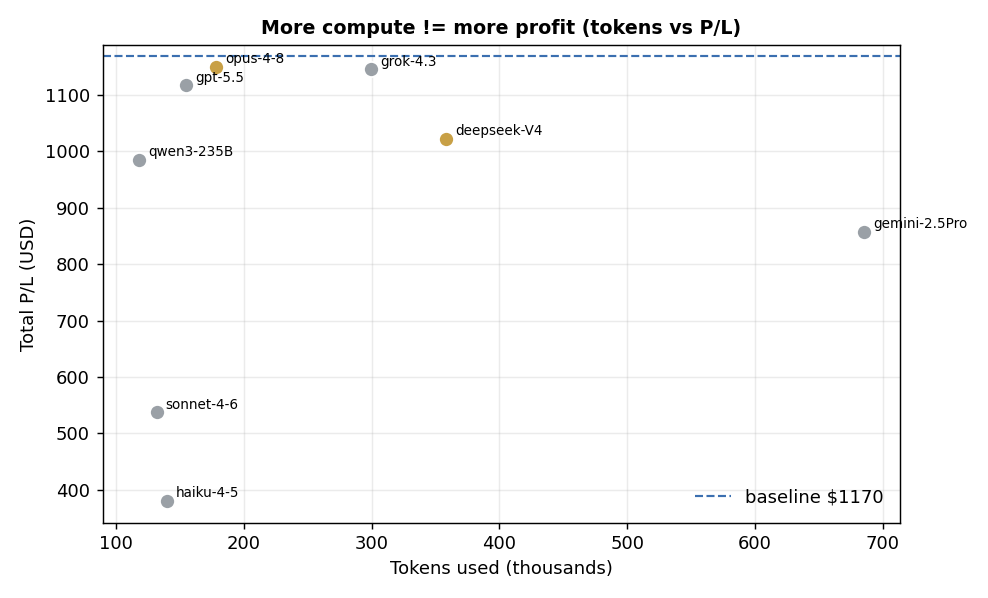
- 合計:約 39 分鐘/207 萬 token/約 $16
- 吃掉最多 token 的是 Gemini 2.5 Pro(68 萬 token/「思考模式」一次很重) ── 但成績卻是中段。
💡 也就是說,「越會思考(越貴越慢)的 AI 越會交易」並不成立。實際運行時每週只判斷一次的話,成本微乎其微(一次幾美分)。
第3篇 總結 ── 不誇大,誠實的結論
✅ 讓 8 個 AI 判斷黃金交易,但沒有人能在總額上超越「全部都做」的基準
✅ 不過 DeepSeek V4(風險最小)、Opus 4.8(平衡最佳) 在風險調整上超越了基準
✅ 聰明的大型收斂成「全部都做」、便宜的小型「砍過頭而自滅」。多數決也沒用
✅ 無法超越的根本原因是 「崩盤」與「可以買的回檔」在開盤時無法分辨
🔑 這個實驗最大的價值,是用自己的 API 成本和歷史數據,打破了「用 AI 就能輕鬆贏」的幻想。AI 不是魔法。但作為「聰明地降低風險的輔助輪」,確實有可用的苗頭(DeepSeek/Opus)。下一階段,會用樣本外數據與紙上交易繼續驗證。
下回預告
到這裡,「該用哪個 AI」的方向大致有了(重風險就 DeepSeek、要平衡就 Opus)。接下來,把這個組合放到 模擬帳戶跑紙上交易。紙上的數字,遇到真實的點差和成交會怎麼變 ── 我會誠實地記錄下來。
⚠️ 再次提醒:本系列不是投資招攬。黃金(XAUUSD)波動很大,自動交易有風險。數字皆為歷史回測,不代表未來。